Microsoft has revealed a novel side-channel attack, dubbed “Whisper Leak,” that can compromise the privacy of conversations with AI chatbots. The technique allows an eavesdropper to infer the topic of a user’s prompt by analyzing encrypted network traffic, even when protected by HTTPS, posing a significant risk to user and enterprise confidentiality.
How the Whisper Leak Attack Operates
The attack targets a fundamental feature of modern AI: streaming mode. When a Large Language Model (LLM) streams its response, it sends data in incremental packets instead of all at once. While this provides a smoother user experience, it creates a unique fingerprint in the network traffic.
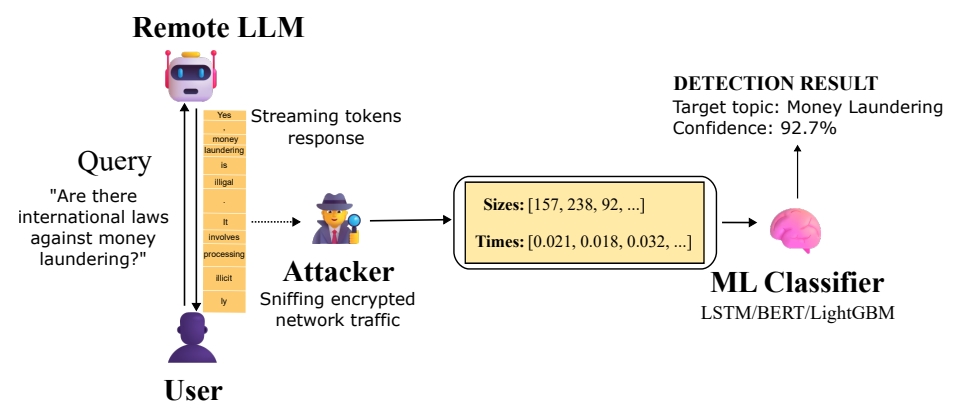
A passive adversary—such as a nation-state actor at an Internet Service Provider (ISP), someone on a shared local network, or a user on the same public Wi-Fi—can observe this encrypted TLS traffic. By extracting metadata like packet sizes and the timing between arrivals, and then using trained machine learning classifiers, the attacker can determine if the conversation relates to a specific, sensitive topic.
The Power of Trained Classifiers
Microsoft demonstrated the attack’s feasibility by training a proof-of-concept binary classifier. This classifier was designed to differentiate between a specific target topic and all other “noise.” Using machine learning models like LightGBM and BERT, the researchers achieved alarming results.
They found that many popular models from providers like OpenAI, Mistral, and xAI were vulnerable, with classification accuracy scores exceeding 98%. This means an attacker monitoring random chats could reliably flag users discussing predefined sensitive subjects, such as money laundering or political dissent, even without decrypting the content.
Real-World Implications and Evolving Threat
The implications are severe. As Microsoft stated, “If a government agency or internet service provider were monitoring traffic to a popular AI chatbot, they could reliably identify users asking questions about specific sensitive topics.” The threat becomes more potent over time, as an attacker collecting more data can refine their classifiers for higher accuracy.
Furthermore, the attack could be combined with more sophisticated models analyzing multi-turn conversations, potentially allowing an attacker to reconstruct large parts of a dialogue with patience and resources.
Deployed Mitigations and User Recommendations
Following responsible disclosure, major AI providers, including OpenAI, Microsoft, and Mistral, have implemented countermeasures. A key mitigation involves appending a random sequence of text of variable length to each streaming response. This masks the true token length, effectively neutralizing the side-channel.
icrosoft also provides recommendations for privacy-conscious users:
- Avoid discussing highly sensitive topics on untrusted networks.
- Use a reliable VPN to obfuscate traffic patterns.
- Opt for non-streaming LLM modes where available.
- Choose AI providers that have publicly implemented these mitigations.
A Broader Landscape of AI Vulnerabilities
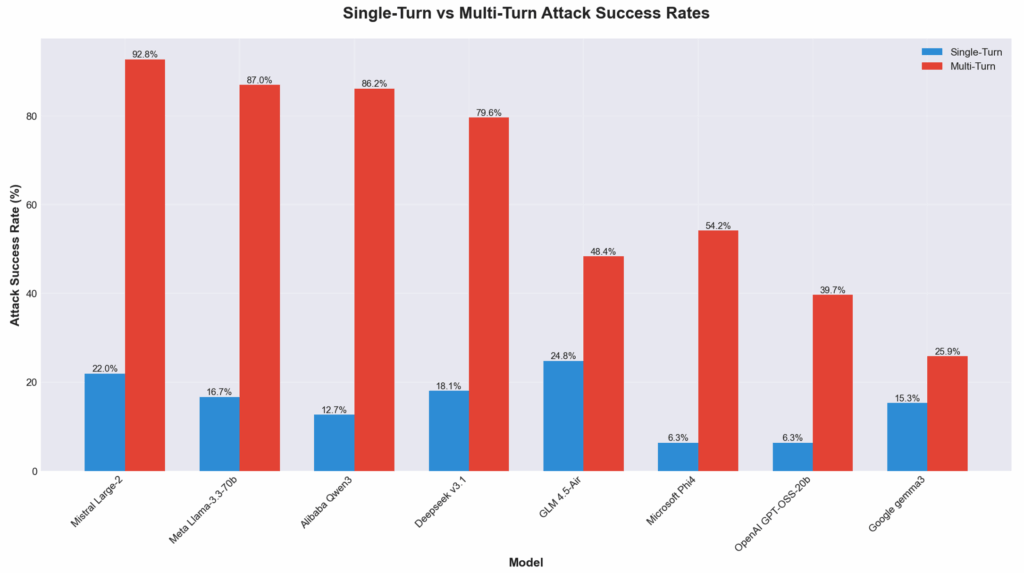
This discovery coincides with new research from Cisco AI Defense, which found that eight major open-weight LLMs are highly susceptible to multi-turn adversarial attacks designed to bypass their safety guardrails.
The researchers concluded that “alignment strategies and lab priorities significantly influence resilience,” with models focused heavily on capability (like Llama 3.3) showing higher susceptibility than those with safety-oriented designs (like Google Gemma 3).

