
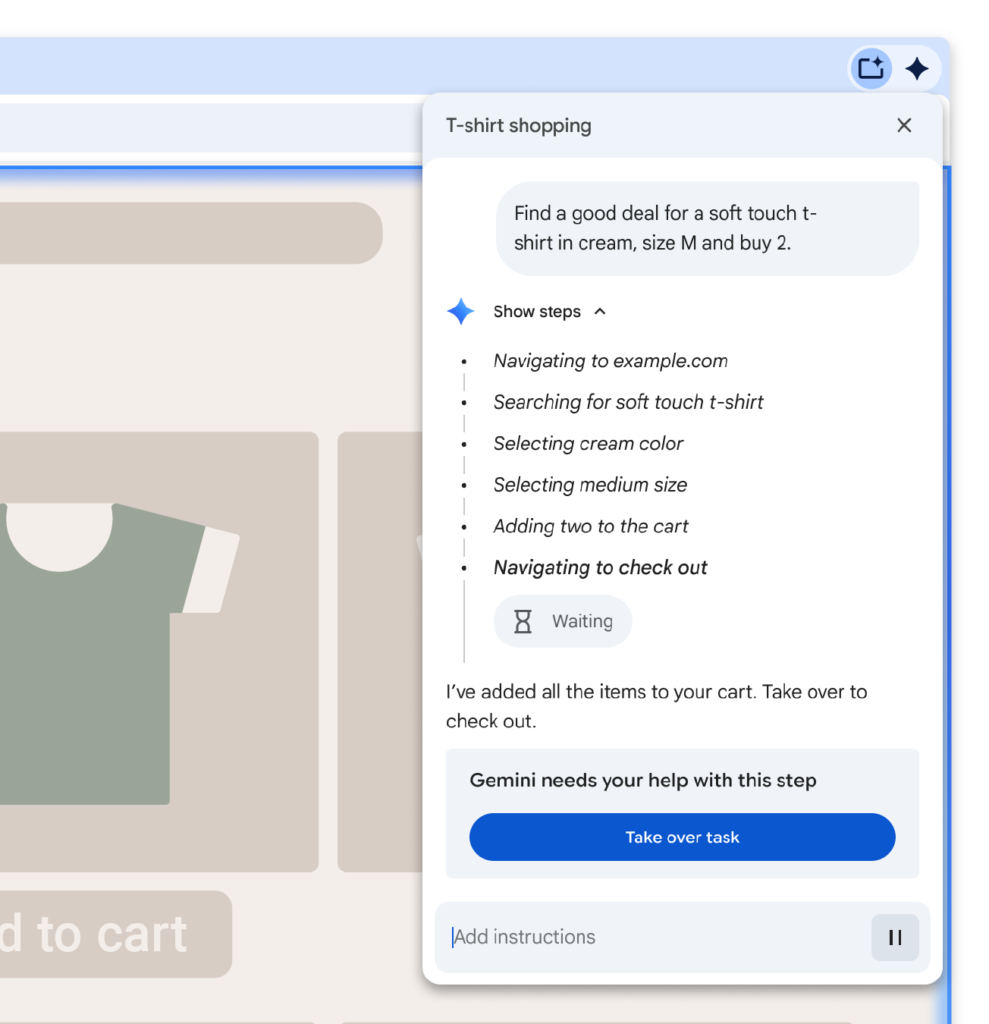
Google has expanded the security framework of Chrome after adding agentic AI features to the browser. The company unveiled a new series of defenses designed to reduce the risk of indirect prompt injections that may occur when an AI agent interacts with untrusted web content.
The most notable addition is the User Alignment Critic, a secondary model that independently evaluates the planned actions of the AI agent. Its role is to determine whether each action aligns with the user’s stated objective. If an action appears misaligned, the feature blocks it and prevents potential abuse.
How the User Alignment Critic Strengthens Protection
According to Google, the feature reviews metadata related to the proposed action rather than the content of the page itself. This prevents the component from being manipulated through malicious prompts hidden inside websites. The critic acts only after the planning phase is complete and can veto actions that may expose data or redirect the agent toward an attacker’s goal.
If the same action fails several times, the system returns control to the user and requests further confirmation.
Agent Origin Sets Limit What Data the Agent Can Access
Another major upgrade is the introduction of Agent Origin Sets, a mechanism that restricts the agent’s interactions to a defined group of sites related to the task the user is performing.
This system separates domains into two categories:
• Read only origins, which the Gemini model is allowed to view
• Read writable origins, which the agent can view and interact with by typing or clicking
This clear separation ensures that sensitive data from unrelated websites cannot be exfiltrated. A gating function decides whether a domain should be added to these sets. The planner must obtain approval from this gating function before including new origins. The gating function is isolated from untrusted content to prevent manipulation.

More Transparency and User Control
The browser now allows users to monitor the agent’s actions through a work log. Chrome requires user approval before visiting sensitive categories of websites, such as banking or medical portals. It also limits actions like purchases, message sending, or signing in using Google Password Manager unless the user confirms the request.
The agent additionally scans every website for indirect prompt injections and works alongside Safe Browsing and on device scam detection to block suspicious material.
Google noted that a prompt injection classifier runs in parallel with the planning model. This classifier prevents actions based on content that appears intentionally crafted to manipulate the AI.
Rewards for Researchers Who Identify Weaknesses
To encourage security testing, Google announced rewards of up to 20 thousand dollars for demonstrations that show meaningful breaches. Successful examples may involve:
• Performing unauthorized actions without asking the user
• Extracting sensitive data without providing the user an opportunity to approve
• Evading protections that were designed to stop the attack
Google emphasized that it is extending familiar principles such as origin isolation and layered defenses while using a trusted model structure to protect Gemini based agent features in Chrome.
Industry Concerns and Research Warnings
The announcement follows a Gartner advisory that urged organizations to block the use of AI based browsers until threats like prompt injections and uncontrolled agent actions are properly addressed.
The report highlighted a scenario where employees might attempt to evade mandatory training by instructing an AI browser to complete tasks automatically.
Gartner stated that AI browsers can greatly change how users interact with websites and automate repetitive tasks, however they also introduce considerable security challenges. The group recommended that CISOs restrict all AI browsers for the foreseeable future.
Meanwhile, the United States National Cyber Security Centre noted that large language models suffer from an ongoing category of weakness known as prompt injection. Experts stated that the issue cannot be fully resolved because current models do not reliably separate instructions from data. Instead, the agency recommended combining LLMs with deterministic safeguards that control system behavior.
Found this article interesting? Follow us on Twitter , Facebook, Blue sky and LinkedIn to read more exclusive content we post.

